本文主要围绕 Llamaindex框架进行描述,是当前该框架的处理方式;源自LlamaIndex工作人员的一篇博文。本文是翻译后的重疾额,原文详见传送门在这里
实现RAG时涉及到的各种技术考虑因素,包括分块(chunking)、查询增强(query augmentation)、层次结构(hierarchies)、多跳推理(multi-hop reasoning)和知识图谱(knowledge graphs)等概念。
分块策略
在自然语言处理中,”分块”是指将文本划分为小而简洁、有意义的 “块”。与大型文档相比,RAG 系统可以更快速准确地定位到较小的文本块中的相关上下文。 分块策略主要取决于分块的质量和结构。确定最佳分块大小需要在获取所有必要信息和保持速度之间取得平衡。 虽然较大的分块可以捕获更多上下文,但会引入更多噪音,并且需要更多时间和计算成本进行处理。较小的分块噪音较少,但可能无法完全捕获所需上下文。
重叠式分块是一种平衡这两个约束条件的方法。通过重叠式分块,在查询过程中很可能能够跨越多个向量检索到足够相关数据,以生成适当环境化响应。一个限制是该策略假设您必须从单个文件中找到所有所需信息。如果所需上下文被拆散在多个不同文件中,则可能需要考虑利用类似文件层次结构和知识图谱的解决方案。
文档层次结构
使用文档层次结构是提升信息检索效率的一个强大方法。将数据设想为RAG系统中的目录,以有序、分级的方式组织数据块,从而让RAG系统能够高效地检索和处理相关联的数据。
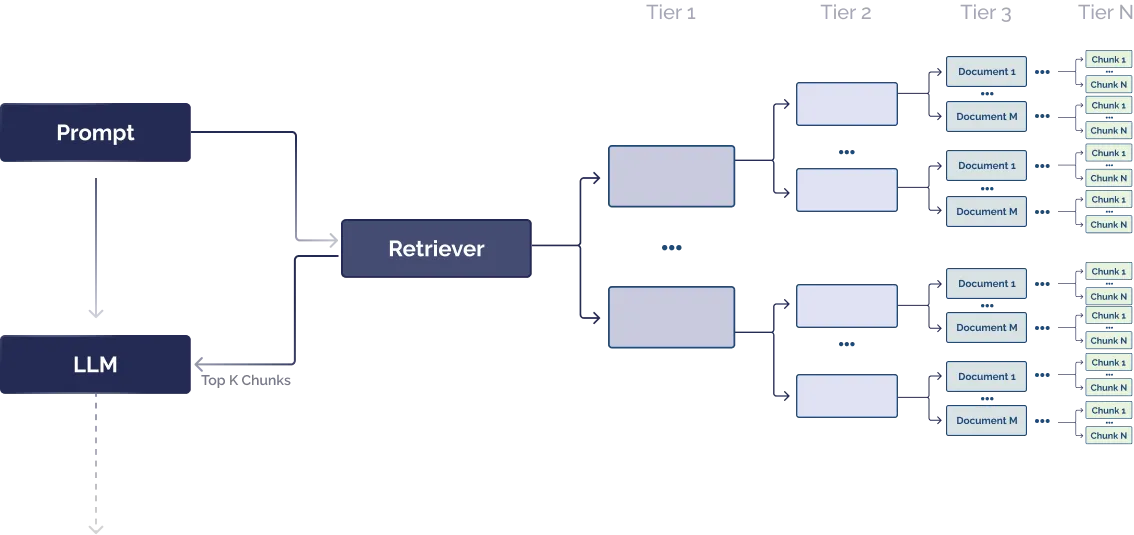
文档层次结构将块与节点关联,并以父子关系组织节点。每个节点包含所包含信息的摘要,使得 RAG 系统能够快速遍历数据并理解应该提取哪些块。
将文档层次结构视为目录或文件目录,通过层次结构作为预处理步骤来定位最相关的文本块,可以改善检索速度和可靠性。这种策略可以提高检索可靠性、速度、重复性,并有助于减少由于块提取问题而导致的幻觉。构建文档层次结构可能需要特定领域或特定问题专业知识,以确保摘要完全与当前任务相关。 所以,在非结构化数据时候添加额外上下文限制条件,使得大语言模型能够进行更确定性信息提取。
知识图谱
知识图是文档层次结构的一个很好的数据框架,可以强制执行一致性。知识图是概念和实体之间关系的确定性映射。与向量数据库中的相似性搜索不同,知识图谱可以一致、准确地检索相关规则和概念,并显着减少幻觉。
将文档层次结构映射到知识图谱中的好处在于,将信息检索工作流程转化为LLM可以遵循的指令。

知识图谱使用自然语言来建立关系,这意味着即使非技术用户也能够通过构建和修改规则以及关联性来控制企业RAG系统。
查询扩充
查询扩充解决了问题陈述不清的问题,这是RAG中常见的一个问题。
RAG要解决的问题是确保任何缺少特定细微差别的问题都能给予适当的上下文以最大限度地提高相关性。糟糕的问题陈述往往是由于语言复杂性而引起的。
解决方案是通过预处理查询并添加领域特定上下文以引用适当部分,将一些特有的属性映射到一个特定部分。
查询规划
查询规划代表着生成子问题的过程,通过适当地给出上下文并生成相应答案来全面回答原始提问。LlamaIndex 使用此策略和其他方法来确定需要回答顶级问题的相关子问题。 以下是 LlamaIndex 的查询规划代理使用的代码片段,用于识别子问题。
/*识别子系统的代码示*/
‘dependencies’: {‘title’: ‘Dependencies’,
‘description’: ‘需要回答给定 query_str 问题所需的子问题列表。
/*如果没有要指定的子问题,则应为空白,在这种情况下会指定 tool_name.’, */众所周知,LLM 在没有辅助的情况下进行推理时存在困难,因此生成子问题面临准确性方面的主要挑战: 鉴于目前大语言模型(LLMs)的发展状况,我们应仅在大语言模型失败时寻求使用外部推理规则进行干预,并不试图重新创造每一个可能存在的子问题。
参考资料
- https://docs.llamaindex.ai/en/stable/optimizing/production_rag.html
- https://openaigpt4v.com/llamaindex-langchain-comparison-2/
- https://www.youtube.com/watch?v=TRjq7t2Ms5I
相关内容的传送门: